Coronavirus Twitter Analysis — Understanding Global Crisis Discourse
Problem
COVID-19 generated unprecedented social media data, but understanding how different cultures processed the crisis required analyzing billions of tweets across languages.
Solution
Built MapReduce-based system to analyze 1.1B geotagged tweets, revealing cultural and linguistic patterns in pandemic discourse through data-driven visualizations.
Key Impact
- •Processed 1.1 billion geotagged tweets (2% of all 2020 tweets)
- •Multi-language analysis: English, Korean, Chinese, Japanese
- •Revealed #corona, #coronavirus, #covid19 dominated global discourse
- •Country and language distribution visualizations
The Problem
COVID-19 was the first truly global pandemic in the social media era. How did different cultures process this collective trauma? Raw social media data can't answer this—1.1 billion tweets is too much for humans to parse, but it's exactly where patterns emerge.
The challenge: Build a system that turns massive, multilingual social data into insights about how humanity responded to crisis.
The Solution
Built a MapReduce-based pipeline to process 1.1 billion geotagged tweets (2% of all 2020 tweets with location data). The system answers two questions:
- Distribution: Which hashtags dominated discourse in each language and country?
- Time Series: How did conversation volume change throughout 2020?
Key product decision: Focus on geotagged tweets only. Trading dataset size for geographic precision meant we could map cultural differences—critical for understanding how local contexts shaped pandemic responses.
How It Works
Two-Stage MapReduce Pipeline:
-
Map Phase (Daily Processing):
- Parse 1.1B JSON tweet objects
- Extract: hashtags, language, country, timestamp
- Generate daily summary files by hashtag
-
Reduce Phase (Aggregation):
- Combine daily summaries into comprehensive datasets
- Group by language and country for distribution analysis
- Time-series aggregation for trend visualization
Engineering detail: Chose MapReduce over single-machine processing because the dataset wouldn't fit in memory. Daily batching allowed parallel processing and fault tolerance—if one day's job failed, no need to reprocess everything.
Multilingual Support: Analyzed hashtags across languages including #coronavirus (English), #코로나바이러스 (Korean), #冠状病毒 (Chinese), #コロナウイルス (Japanese). UTF-8 encoding handled diverse character sets without data loss.
Key Findings
1. Global Hashtag Dominance: #corona, #coronavirus, and #covid19 emerged as the dominant discourse markers across all languages and countries throughout 2020.
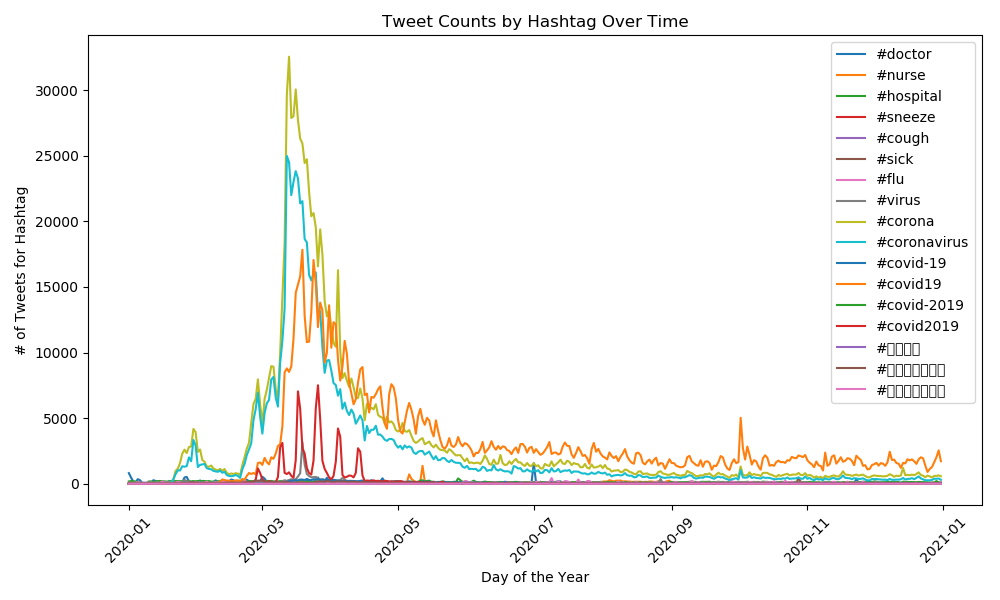
2. Language-Specific Patterns: Distribution analysis revealed distinct linguistic communities—English, Korean, Chinese, and Japanese speakers had different discourse volumes and peak activity periods.
3. Geographic Variance: Country-level analysis showed regional differences in pandemic discussion intensity. Not all countries talked about COVID equally—geography shaped digital discourse.
Key Product Decisions
Why MapReduce? Product thinking: Need to process data that doesn't fit in memory. MapReduce enables fault-tolerant, parallelized processing—if one day's batch fails, rerun just that day, not the entire pipeline.
Why geotagged tweets only? Product thinking: Geographic precision > dataset size. Understanding where conversations happened is more valuable than processing every tweet without location context. Cultural differences emerge from geographic segmentation.
Why focus on distribution + time series? Product thinking: Users want two answers—"What was most popular?" (distribution) and "How did it change?" (time series). These two views tell a complete story about discourse evolution.
Key Challenges
Challenge 1: Scale Without Infrastructure The Problem: 1.1B tweets won't fit in memory on standard hardware.
The Solution: MapReduce pattern with daily batching. Python's json library + argparse CLI made processing distributed across time rather than machines.
Challenge 2: Multilingual Character Encoding The Problem: Hashtags in Korean, Chinese, Japanese require different character sets.
The Solution: UTF-8 encoding from the start. Ensured all text parsing preserved non-Latin characters without corruption.
Impact
What We Learned:
- #corona, #coronavirus, and #covid19 dominated global pandemic discourse
- Language communities showed distinct patterns—not everyone talked about COVID the same way
- Geographic data revealed regional variance in discussion intensity
Product Value: Demonstrated how massive-scale data analysis can reveal cultural patterns invisible in smaller datasets. Built empathy through quantitative analysis of collective trauma.
What Could Be Further Improved
Short-term
- Sentiment Analysis: Add emotion detection to understand how people felt, not just what they said
- Interactive Visualizations: Build web dashboard for exploring data dynamically
- Export Reports: Generate summary PDFs with key findings
Long-term
- Real-Time Analysis: Stream live tweets for ongoing discourse tracking
- Network Analysis: Map how hashtags spread across geographic and linguistic communities
- Predictive Modeling: Correlate Twitter volume with epidemiological data (case numbers, hospitalizations)
- Misinformation Detection: Identify and track false information propagation patterns
Stack: Python 3, MapReduce, JSON, Matplotlib, argparse
Timeline: 2020 dataset (Jan-Dec), analysis conducted 2024
Dataset: 1.1 billion geotagged tweets (2% of all 2020 tweets with location data)
Key Output: Distribution and time-series visualizations revealing #corona, #coronavirus, #covid19 as dominant pandemic hashtags across languages and countries